|
Advanced Tips & Tricks
This article states advices for experienced users who need some more advanced capabilities.
-
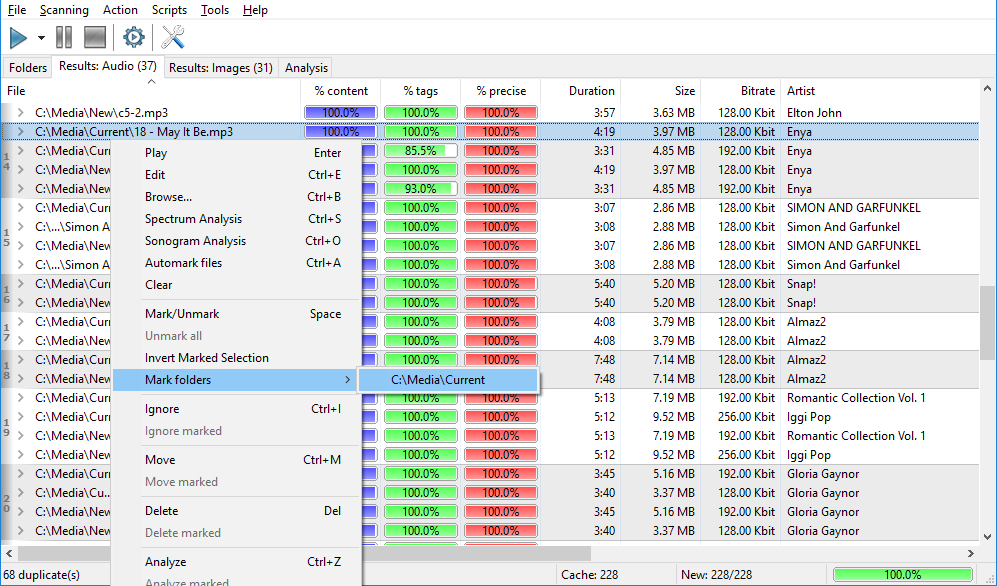
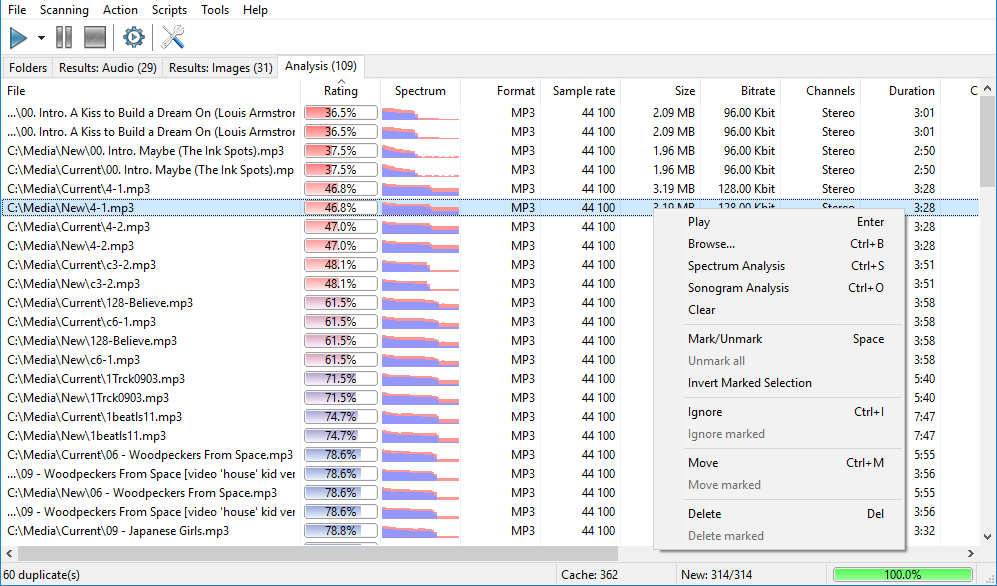
To generate file cache without actual comparison of those files, you can mark all selected folders in the collection as the same group number (for instance, #1) and run scanning. Files will not be compared, but the cache will be built. You’d want this if you needed to preliminarily create a cache of your permanent collection for further comparison of new files with it, or if you need to save a cache or rebuild it.
-
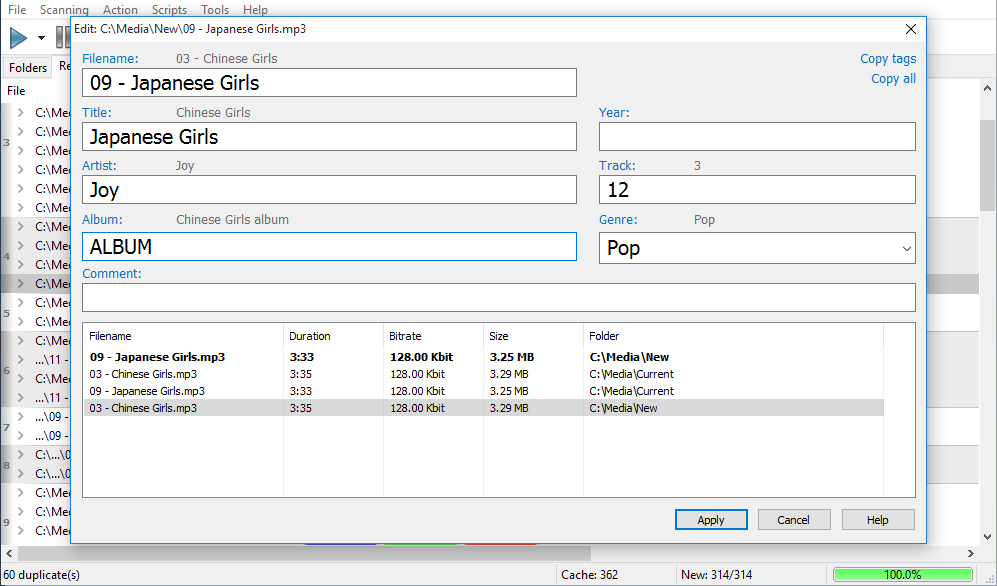
Cache files are saved here: "%appdata%\Similarity\cache.dat". You can copy this file or replace it as long as the program is stopped to prevent changes in the file.
-
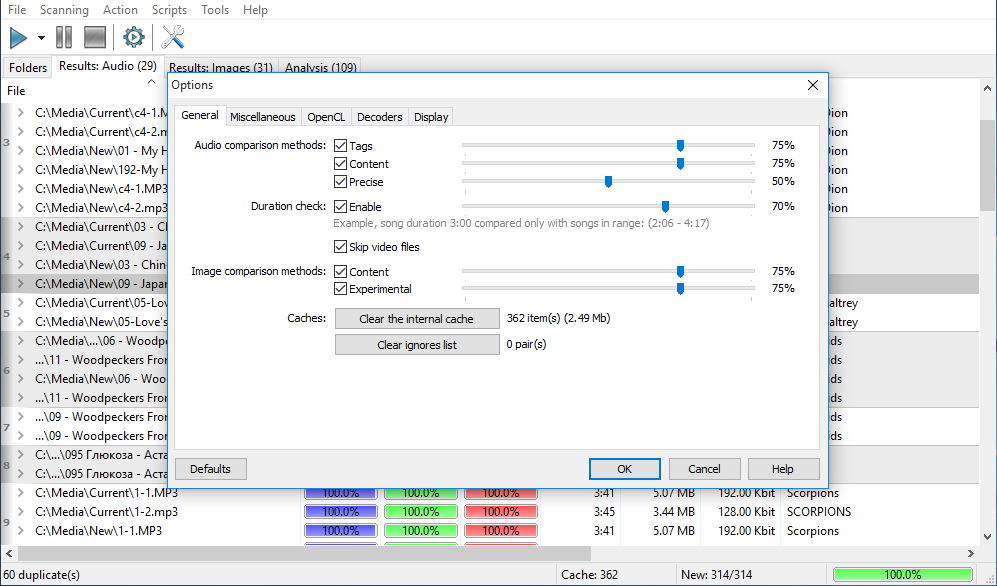
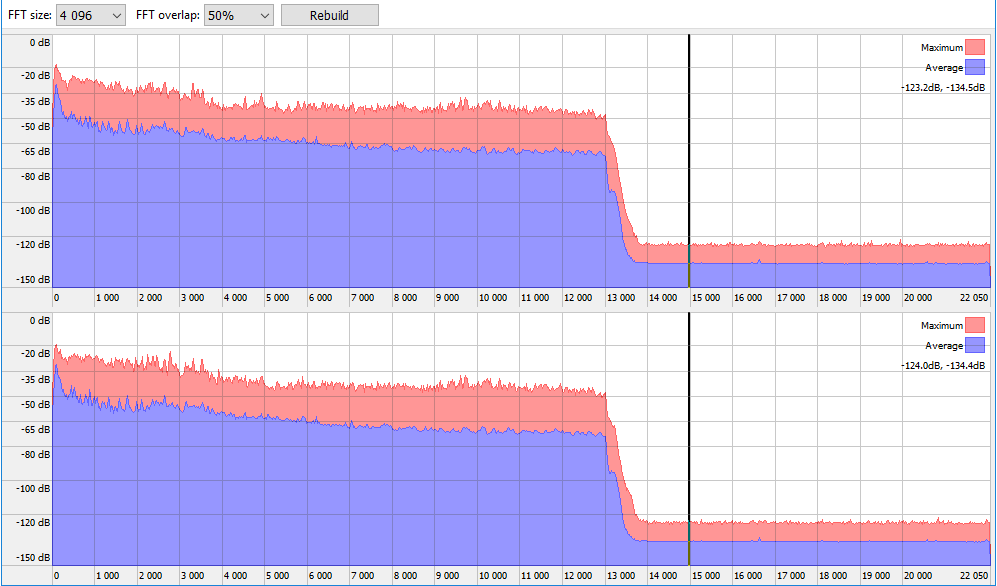
The approximate memory required to cache 1 file is 8.5Kb for the "Precise" algorithm and 9Kb for the old content based algorithm plus from 40 bytes to 1Kb of memory for tags and other file information. That is why when you work with large collections it is recommended to turn off the old content based algorithm - this saves up to twice as much memory. For example: if all algorithms are enabled, the scanning of 100,000 files takes 100,000 x (8.5 + 9 + 1) = 1,850,000Kb = 1,85Gb of RAM. And if you leave only the "Precise" algorithm on, it takes 100,000 x (9+1) = 1,000,000Kb = 1Gb of memory. Tag information is always saved even if you didn’t turn on this algorithm, because tags are used to display results.
-
Similarity keeps logs of its operation and saves them to "%appdata%\Similarity\logs" folder. Logs reflect operation errors, reasons for skipped files during scanning (for example, crash or hanging of a particular decoding process) and the detailed information on the issue. If you have faced with any errors while working with the program, please send log files to us. This will help us greatly to locate the source of problems.
|
|
Downloads
Premium version
Latest news
|